Case Studies
Branding Cat - Social Listening
As a cofounder with a marketer we were looking to bring the dopamine rush of achievement unlocking to social marketing to make people's jobs fun.


Above: Bringing a dopamine rush to a tedious task
We knew that supplying a reliable product is key to retaining customers. In order to be a professional company it is important to use professional tools to perform extensive compilation checks and quality assurance. We used Haskell and our intimate knowledge of GitLab as a project management and issue tracking board to provide a reliable product.
Haskell provides an exceptional typing system which prevents a large class of bugs entering the app even before pushing to production. This causes development to be slow by moving time spent on testing into the development stage. The main issue is framing generic functions into the correct monadic container. Pure code is easy to write because the type system is more consistent with other langauges if the function is fully pure. It's equivalent to Ocaml in many ways at this point apart from the access to guards and implied cases within function declarations.

Above: Logging in
Ocaml and Rust were considered as an alternatives as they have a strong type systems and functional approaches. Rust had to be looked over as although it has amazing community support, the manual memory management aspect slows development too much with no gain. A garbage collector adds or removes nothing to an application's reliability as Rust has memory checking as it's core feature. Unlike a strong type system which reduces bugs to provide a good customer experience, having a garbage collector or not affects only performance. Server costs are miniscule in comparison to development costs. The customer will not notice that we have 2 slightly larger servers than if we had built in Rust. An extra $100-200 a month in server costs would translate to thousands of dollars in extra time spent developing to appease the borrow checker.

Above: Scrolling through posts
React Native was used to provide a web dashboard and mobile app within a short timeframe. It was decided not to use Flutter, as although Flutter offers better performance metrics on mobile it renders many elements on the web as a canvas and we wanted a solid web experience. We were confident in our skills to adopt any technology platform no matter the underlying language and so this aspect did not factor in at all.


Above: React Native produces a working native mobile app with minimal time investment
Register on BluePanther.agency
Care Scheduling Manager
Unlike regular scheduling domiciliary care requires allowances for travel time which makes it very difficult to match available hours to call locations. You cannot simply have someone who comes in at 09:30 am quickly fill in at a certain location because they need to first get there and then the order of the clients directly affects how much travel time and fuel consumption will be accrued over the course of a day.
We reviewed the problem by understanding how they currently performed the task on paper.


Above: Designed to imiate original paper workings
A custom solution was tailored to provide efficiency improvements while keeping their existing solution strategy except in digital form. Multiple views were created so that individual appointments could be tracked during the week. Before the week commenced an overview view was created to facilitate fast schedule building speeds. In order to justify development costs it was necessary to reduce ongoing staff labour costs.
The system began as a prototype integrated with a CRM system. This allowed a focus on designing the core operational parts of the system. Eventually the system was rewritten to be fully self contained, however it was managed in stages to ensure success of the project. A small section would be moved across and checked in daily operation until reliability had been proved.
At the forefront was also a focus on failsafes and fallbacks. Failsafes to prevent missed appointments, and fallbacks to keep the business running through power cuts or technology failure. Failsafes included not just the obvious unassigned appointments, but appointments that would be difficult to fulfill such as singles (requires 1 carer) in between doubles (requires 2 carers). The business only used one car for 2 members of staff to cut fuel costs, and having a single in between doubles would be a complete loss of one set of wages for a few hours.
Fallback methods included printed sheets of up to date appointment in both appointment and overview form. It was still possible with a pen to amend a sheet using the old working style and (slowly) redistribute schedules. Although this method of working was never used it doubled up as a secondary check.
The computer also ran it's own internal checks continuously comparing the current schedules with rebuilt from scratch schedules so that in the event of coding mistakes it was more likely to cause chaotic behaviour rather than subtle hard to spot mistakes. As witnessed with the Post Office Horizon disaster subtle mistakes can remain hidden for long periods. There was also a policy of suspecting a computer error before simply blaming human error. While creating extra work for a number of false alarms, it also promoted an environment of improvement where new failsafes were implemented to detect mistaken button presses.
The system remained in 24/7 usage until the company was sold. Between 30-50 carers daily were scheduled for consistently for years.
Multiple Translation Management
Managing multiple translations requires automated processes to ensure that the translations are kept synchronised with each other. Price changes and additions to english text need to be monitored every time the site changes. It's also important to make sure the site is converted to a fixed, static copy so that it loads quickly on mobile devices. Every second longer a page takes to load massively increases the chance of visitors clicking back before it appears.
The site also needed to be easy to maintain even with many different translations. The business was not a large business but a mid sized business looking to expand and would be unable to hire dedicated staff to manage translations daily.


Above: Spanish translation
The solution was to use a directory to store all translation text coupled with existing correctness verification technologies in the node.js & next.js platforms. For any checks that couldn't be automatically embedded into the compilation stage, small scripts were provided to manually run quick checks.
It took a while for the translation team to understand the file format and associated manipulation utilities, however any mistakes were immediately flagged long before the site was anywhere near production. Because of where the checks were embedded in the compilation stage the live website would have refused to accept the bad translation edits anyway. Most of the issues were misunderstandings over naming conventions with the compiler requiring a very strict naming convention and directory layout. However once compiled we could guarantee that every page would render in the new language without needing to manually check it. Manual proofreading was performed but the purpose was to ensure reader flow not notice site breaking issues.
The translation was not just limited to the sales pages but also the user account area where it had to interact with ecommerce code. This is where the translation files were converted to node.js compatible type verification information and the loading process was converted to newer next.js constructs for a more consistent page loading experience.
The process could be further streamlined by integrating automated translation APIs and proofreading stages together with a simple web based frontend that exported directly to new translation files. This would remove the issues over needing to understand naming conventions and which parts of the file need to be edited and which parts are used internally by the code.
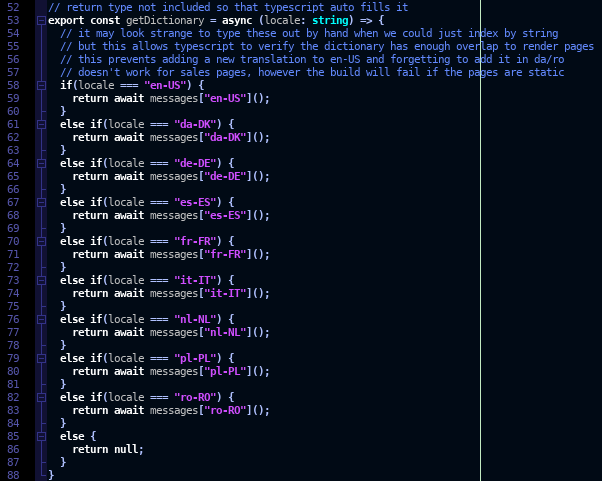 Above: Automatically check that entries in the dictionary are available on all translations
Above: Automatically check that entries in the dictionary are available on all translationsBreak Distribution Calculation
Scheduling breaks is often ignored as it is considered a small allotment of time and as long as they don't overlap it feels as though it shouldn't affect the overall service level. In a large call centre and/or on days with specific peak times it can make a big difference to the average time to answer. Counterintuitively some of the lower call volume periods can cause problems especially if during your peak call period you have 2 sets of staff shifts overlap giving you a sudden boost in agent numbers.
Break times have limitations on their location from a legal standpoint and must be fairly distributed for all staff members. However within those confines there is a good amount of room to look for an optimal distribution to lower the average time taken to answer calls and lower callers hanging up prematurely.
Two methods were chosen to search for the optimal distribution, simulated annealing and the more classical integer linear programming. The simulated annealing method was quickly discarded as it would fail to reach the best solution and it was unclear how good the solution it had found really was. Linear programming is the holy grail of optimization but often is too taxing for the computer on large problems. Fortunately due to the company size, the problem was still tractable on standard hardware.
The staff shift times and limits of their break time locations were encoded as a number system and associated constraints. Average answer time was precomputed and encoded as further constraints as the graph it produces is non linear. Sampling points were within 10 minutes of accuracy however if the problem was to grow larger a wider sample time could have been used and the function converted to an approximate linear output between those points. This produces a non optimal result but perhaps good enough when compared with the time spent by a person to replicate a similar result.
In this case the underlying shift times were all largely pre approved and written into contracts. If the company had relied much more heavily on part time staff with less rigid working hours then the problem would have become much more complex, but there would also many be more exciting solutions to investigate. Especially if break time calculations were run alongside choosing when staff should come to work.
 Above: Erlang Formula
Above: Erlang Formula